
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Jndi DataSource
- Reading HttpServletRequest Multiple Times
- requestheaderdto
- Srping MVC
- Java Graphql
- AfterMapping
- 데이터 압축
- java
- Socket is closed
- Request Body 여러 번 사용
- Graphql Client
- WildFly
- graphql
- NoUniqueBeanDefinitionException
- mTLS
- tomcat jndi
- Sub Bytes
- Tomcat DBCP
- Unchecked Exception
- mapstruct
- Open Close Principal
- Java Singleton
- Checked Exception
- 개방 폐쇄 원칙
- 이중정렬
- try - with - resources
- Java Rest
- HandlerMethodArgumentResolver
- 상호 인증
- 바이트 절삭
- Today
- Total
Developer Sang Guy
[Mysql]Full Text Search 본문
Mysql에서 제공하는 Full Text Search 기능은 지정한 FullText Index 컬럼에 저장 된 자원을 설정에 맞게 절삭하여 인덱스를 생성하며 해당 인덱스를 활용하여 더 빠르게 조회 결과를 추출한다.
최초 테이블 구성

CONTENT 컬럼 FULLTEXT 인덱스 설정
ALTER TABLE `002`.`tb_fts_test` ADD FULLTEXT INDEX `IDX1` (`CONTENT`) INVISIBLE;

CONTENT 컬럼의 Key가 MUL(Multiple Occurences Column)로 변경되었다.
MUL이란?
다중 발생 컬럼이라는 의미로 중복 된 값이 발생할 수 있는 인덱스라는 의미로 기본키도 외래키도 아닌 그냥 일반 인덱스
https://dev.mysql.com/doc/refman/8.0/en/show-columns.html
테스트 데이터 INSERT

생성 된 인덱스

생성 된 FULLTEXT INDEX 확인하는 방법
SET GLOBAL innodb_ft_aux_table = '스키마 이름/테이블 이름';
SET GLOBAL innodb_optimize_fulltext_only=ON;
OPTIMIZE TABLE 테이블 이름;
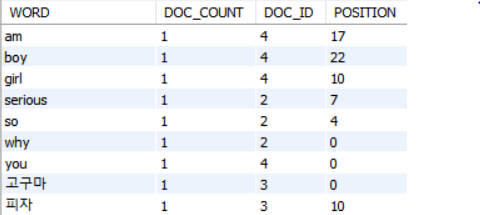
절삭되어 생성 된 인덱스를 보면 띄어쓰기를 기준으로 3개 문자 이상의 단어로만 구성된걸로 확인된다.
토큰의 Default 최소 사이즈는 3이다.
select CONTENT from tb_fts_test where match CONTENT against ('why');
select CONTENT from tb_fts_test where match CONTENT against ('고구마');


인덱스로 등록 된 단어는 정상적으로 조회가 가능하지만 아래와 같이 2글자로 된 인덱스로 등록되지 않은 단어는 조회가 되지 않는다.
select CONTENT from tb_fts_test where match CONTENT against ('so');
select CONTENT from tb_fts_test where match CONTENT against ('피자');
show variables like '%ft_m%';
위 쿼리를 사용하여 확인할 수 있으며 ft_max_word_len, ft_min_word_len는 MyISAM에 대한 설정이고
innodb_ft_max_token_size, innodb_ft_min_token_size는 InnoDB에 대한 설정이다.
https://dev.mysql.com/doc/refman/8.0/en/fulltext-fine-tuning.html
tb_fts_test 테이블은 InnoDB 이므로 innodb_ft_max_token_size, innodb_ft_min_token_size 설정을 바라본다.

해당 설정은 my.conf 파일을 수정하여 적용할 수 있다.
[mysqld] 아래 영역
innodb_ft_min_token_size=2
ft_min_word_len=2
my.conf 파일 수정 후 변경 된 인덱스
변경 후 2글자 단어 조회 결과
select CONTENT from tb_fts_test where match CONTENT against ('so');
select CONTENT from tb_fts_test where match CONTENT against ('피자');


그런데 사이즈를 2로 변경하기 전이나 지금이나 단어 사이즈에 문제가 없는데도 인덱스로 등록되지 않는 단어가 있다.
"You Are a Girl I Am a Boy" 컬럼의 "Are" 단어가 등록되지 않았다.
이는 불용어 테이블에 "Are"가 등록되어 있어 해당 단어는 인덱스 생성에서 무시된다.
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_DEFAULT_STOPWORD;

서비스에 따라 STOPWORD를 무시해야 할 경우도 있다.
해당 설정 방법은 아래와 같다.
일시 적용
mysql> set global innodb_ft_enable_stopword = OFF;
mysql> set session innodb_ft_enable_stopword = OFF;
영구 적용
[mysqld] 아래 영역
innodb_ft_enable_stopword = OFF;
설정 후 인덱스

STOPWORD로 지정되어 있던 "are"가 인덱스로 생성 된 것을 확인할 수 있다.
Search Type
1. IN NATURAL LANGUAGE MODE (자연어 검색)
기본(아무 타입 설정 없이) 또는 자연어 검색을 사용할 경우 검색 단어와 FULLTEXT INDEX 생성 된 값과 동일한 값이 있을 경우에 조회가 가능합니다.
select * from tb_fts_test where match content against ('고구마' IN NATURAL LANGUAGE MODE);
select * from tb_fts_test where match content against ('고구마 피');

select * from tb_fts_test where match content against ('고구' IN NATURAL LANGUAGE MODE);

2. WITH QUERY EXPANSION (쿼리 확장 모드)
쿼리 확장 모드를 사용하면 첫 번째 검색 결과의 토큰들과 가장 연관성 있는 항목들 까지 같이 조회할 수 있습니다.
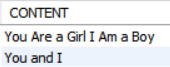
예시를 설명하기 위해 "피자 맛있어", "You and I" 데이터를 추가했다.

select * from tb_fts_test where match content against ('고구마' WITH QUERY EXPANSION);

검색 단어 "고구마"는 포함되어 있지 않지만 첫 번째로 조회 된 "고구마 피자" 텍스트 중 피자 토큰과 연관있는 "피자 맜있어" 컬럼까지 같이 조회되었다.
select * from tb_fts_test where match content against ('girl' WITH QUERY EXPANSION);
검색 단어 "girl"은 포함되어 있지 않지만 첫 번째로 조회 된 "You Are a Girl I Am a Boy" 텍스트 중 "you" 토큰과 연관있는 "You and I" 컬럼까지 같이 조회되었다.
3. IN BOOLEAN MODE
BOOLEAN MODE에서 제공하는 BOOLEAN 연산자를 사용하여 기능을 확장할 수 있다.
제공하는 연산자는 아래와 같다.
1. + (AND 연산)
select content from tb_fts_test where match content against ('+you +and' IN BOOLEAN MODE);
"you"와 "and"가 둘 다 포함되어 있는 텍스트
2. - (NOT 연산)
select content from tb_fts_test where match content against ('+you -and' IN BOOLEAN MODE);
you는 있지만 and는 포함되어 있지 않은 텍스트
tip : NOT 연산 단독으로 사용할 수는 없다.
ex) select content from tb_fts_test where match content against ('-you' IN BOOLEAN MODE);
you를 포함하지 않는 모든 텍스트
3. 공백 (OR 연산)
select content from tb_fts_test where match content against ('you 고구마' IN BOOLEAN MODE);
you 또는 고구마가 포함되어 있는 텍스트
4. <, > (우선 순위 연산)
select content from tb_fts_test where match content against ('+you <boy' IN BOOLEAN MODE);
you가 포함되어 있는 텍스트 중 boy가 포함 된 텍스트를 우선 순위 가장 낮게
select content from tb_fts_test where match content against ('+you >boy' IN BOOLEAN MODE);
you가 포함되어 있는 텍스트 중 boy가 포함 된 텍스트를 우선 순위 가장 높게
5. () (하위 표현 연산)
select content from tb_fts_test where match content against ('+you +(<boy >and)' IN BOOLEAN MODE);
you 및 boy가 포함되어있거나 you 및 and가 포함되어 있는 텍스트 중 boy가 and가 포함 된 텍스트를 우선 순위 높게
6. * (와일드 카드 연산)
select content from tb_fts_test where match content against ('y*' IN BOOLEAN MODE);
단어의 시작이 y로 되어있는 단어를 포함하고 있는 텍스트
tip : 와일드 카드 연산은 설정 되어 있는 최소 토큰 사이즈보다 작거나 STOPWORD에 등록 된 단어와 상관없이 동작합니다.
7. "" (일치 연산)
"" 안에 있는 단어 또는 문자열과 동일한 텍스트
select content from tb_fts_test where match content against ('"고구마 피자"' IN BOOLEAN MODE);
텍스트 안에 "고구마 피자"와 동일한 문자열이 있는 텍스트
tip: "고구마 피자 맛있어" 텍스트는 검색되지만 "피자 고구마 맛있어"는 검색되지 않는다.
'Others' 카테고리의 다른 글
| [Wildfly] 로그가 안나와요(sl4j 충돌) (0) | 2023.03.30 |
|---|---|
| [Mysql]Full Text Search ngram (0) | 2023.02.17 |
| [MAVEN] JAR, WAR 생성 시 Resource File Exclude (0) | 2023.01.26 |
| [Apache] ServerName, ServerAlias 동작 방식 (0) | 2023.01.12 |
| SRI 생성 방법 (0) | 2022.12.16 |

